La première chose que l’on va faire c’est configurer les services; en tout cas, ceux qu’on peut 🙂
Pour ça, dans le menu de gauche on clique sur les petits engrenages

Le serveur MQTT
Alors, pour l’instant, on va le laisser un peu de côté en termes de jeu. Mais je vais juste te montrer sa configuration si tu souhaites le connecter à un serveur MQTT.
On clique sur le bouton “MQTT” et ça laisse apparaitre les paramètre pour se connecter à un serveur MQTT.
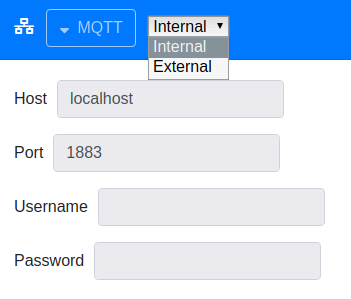
Tu as 2 choix possibles, soit le serveur MQTT est géré en interne par mosquitto, soit tu peux te connecter à un autre serveur MQTT. Ça peut être intéressant par exemple si tu veux te connecter à un “réseau” snips existant car Rhasspy peut aussi s’appuyer sur le même protocole Hermes-MQTT que snips.
Choix initial : Internal
Laissons Internal pour le moment. Je reviendrai dessus quand je ferai mes tests avec snips
Audio recording
C’est ici qu’on définit comment configurer l’enregistrement depuis le micro.
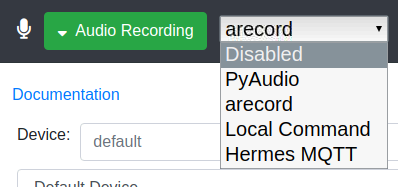
Alors on a pyAudio. C’est une librairie qu’on utilise en python pour enregistrer ce qui vient d’un microphone par exemple. Ça peut être pratique si on veut écrire son propre script pour récupérer la voix et faire des traitements dessus. Cette option offre la possibilité d’envoyer l’audio sur un serveur distant pour traitement de reconnaissance vocal. Je n’en sais pas plus.
Ensuite, nous avons arecord. Classique, on connait l’outil et c’est celui que je vais activer.
Ensuite, nous avons Local Command. Une option qui peut être intéressante par exemple si on souhaite customiser la ligne de commande de l’outil d’enregistrement.
Et le dernier Hermes MQTT. Je n’ai pas testé mais ce n’est pas impossible que ce soit pour récupérer l’audio de hermes/audioServer/<siteId>/audioFrame.
Le choix initial : arecord
Un classique, on maitrise l’outil.
Wake Word
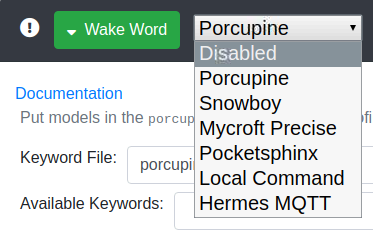
Alors pour être totalement transparent, je n’ai toujours utilisé que le wake word par défaut de snips. Donc c’est un sujet que je n’ai pas encore approfondi.
Néanmoins, Porcupine semble être utilisé par les personnes sur le forum j’ai l’impression.
Snowboy n’évolue plus je crois.
Mycroft Precise vient du projet Mycroft qui est un assistant vocal online (doit se connecter à internet). Néanmoins, je pense que la détection d’un wake word ne devrait pas avoir besoin d’Internet. A tester.
Pocketsphinx, alors lui, je le connais pour avoir essayé de l’utiliser à mes début en reconnaissance vocale et c’était une catastrophe. Bon, je ne connaissais pas trop non plus le sujet, mais les perfs étaient médiocres. Donc, je reste un peu sur cette idée. Peut être faudrait il que je réessaie un jour.
Il reste Local Command et Hermes MQTT qui ont à peu près la même fonction à chaque fois. Local Command permet de faire appel à un programme exterieur et Hermes MQTT qui permet de s’appuyer sur le protocole Hermes (compatible snips). Je ne les listerai donc plus pour les prochains services.
Le choix initial : Disabled
En effet, pour le moment je découvre l’outil. Je reviendrai sur ce point plus tard quand je souhaiterai lancer mon pilote 🙂
Speech To Text
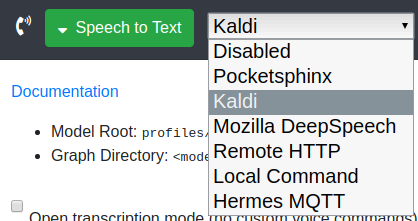
Alors là, il y en a 2 qui me font briller les yeux comme un gamin dans un rayon de jouet : Kaldi et Mozilla DeepSpeech
Kaldi, je le connais pour l’avoir déjà un peu utilisé dans un autre contexte et en plus, je crois que snips s’appuyait plus ou moins dessus. C’est un outil vraiment fiable et efficace s’il est bien configuré et surtout avec de très bon modèles disponibles. Je sais qu’il y a un modèle français qui traine sur internet qui a été très bien entrainé. Je vais regarder ça.
Le second donc c’est Mozilla DeepSpeech. Ça fait longtemps que j’attends un vrai projet pour commencer à jouer avec. Alors, je ne vais pas rentrer trop dans le détail mais DeepSpeech c’est du deep learning, c’est à dire basé sur un réseau neuronal d’intelligence artificielle. Ce qui est important en Deep Learning pour un résultat très efficace, c’est la quantité de données. Il faut qu’elle soit très très très importante. Plus que pour du machine learning standard. Et là, il existe un dataset FR qui fait déjà pas loin de 10 Go . Tu vas me dire : C’est énorme ! Oui, mais non. Ce n’est pas encore assez. Mais par contre, une fois qu’on aura le nombre d’heures nécessaires pour avoir un modèle fiable, alors cette technologie dépassera toutes les autres en reconnaissance vocale. Et en Offline en plus ! Bon, j’ai des doutes que ça tourne correctement sur un raspberry. Ce sera à tester. Par contre, rien ne t’empêche de créer ton propre modèle mais cela prend beaucoup beaucoup de temps à préparer ce genre de dataset. Mais avec juste les phrases nécessaires à reconnaitre, le modèle serait plus petit et donc plus accessible sur un raspberry.
Choix initial : Kaldi
Je pense qu’il a été testé sur raspberry par l’équipe de développement et je sais qu’il est relativement efficace.
Intent Recognition
Il y en a surtout 2 qui vont nous intéresser : Fsticuffs et Fuzzywuzzy . Car ce sont les 2 plus rapides en termes de traitement.
| Outils | Nombre de phrases | Vitesse d’entrainement | Vitesse de reconnaissance | Fléxibilité |
|---|---|---|---|---|
| fsticuffs | 1M+ | Très rapide | Très rapide | ignore les mots inconnus |
| fuzzywuzzy | 12-100 | rapide | rapide | Reconnaissance de chaines de caractères |
J’ai repris le tableau du site de rhasspy.
Le premier est capable de gérer des millions de lignes et de reconnaitre en quelques millisecondes. Par contre, il faut que les phrases soient à l’identique sinon pas de reconnaissance d’intent. Un peu juste je pense pour un assistant vocal. Parfois, juste un mot compris de travers, et l’intent ne serait pas reconnue… A tester
Le second est plus limité en termes de phrase mais par contre, il ne cherche pas spécifiquement la phrase exacte, mais à l’aide d’un algorithme, il va plutôt chercher si une phrase s’en rapproche réellement. Il réagira donc mieux au rôle d’assistant vocal. De plus, Il intègre un paramètre de confidence. Il faut voir ça un peu comme un paramètre qui définit à partir de quel pourcentage (que la phrase soit proche) on estime que c’est validé.
Choix initial : Je vais essayer les 2 et me faire mon avis 🙂
Edit: Pour le moment, j’utilise fsticuffs avec un fichier sentences.ini optimisé. Pour plus d’info, c’est dans cet article
Text To Speech
Alors là, le choix va être vite fait (malheureusement). Espeak, ça fait une voix de robot des années 80. Flite n’existe pas en français. Il nous reste donc picoTTS (celui que l’on connait avec snips) et MaryTTS qui nécessite un serveur web distinct.
Choix initial : PicoTTS
On le connait, on ne sera pas dépaysé pour les tests. Dans le paramètre Language, on oubliera de mettre fr car sinon, on va avoir une voix anglaise qui cause du français. Ça fait saigner les oreilles…
Audio Playing
Hé bien ce sera donc aplay. Outil que l’on connait bien sur ce blog car très utilisé dans les tuto dur les respeaker.
A noter qu’il y a la possibilité de définir la sortie audio sur un périphérique spécifique. Ça peut être intéressant dans certains cas.
Choix initial : Aplay
On connait l’outil
Dialogue management
Alors la gestion des dialogues c’est : qui gère les dialogues. Soit c’est rhasspy, soit c’est sur MQTT via Hermes-MQTT.
Choix initial : Hermes MQTT
Pour commencer, je vais passer sur un dialogue management que je connais puisque c’est celui de snips, Hermes MQTT. Je pense que je ferai un article dédié sur ce sujet quand j’aurai assez joué avec 🙂
Sauvegarde de la configuration
Il nous reste plus qu’à sauvegarder tout ça en cliquant sur Save Settings.
Et si tout se passe bien, Rhasspy redémarre. Si on retourne sur la page d’accueil, on peut désormais voir notre menu des services avec des icônes vertes, donc des services en état de fonctionnement.

Par contre, il nous demande de télécharger des fichiers manquants. Ce qu’li va donc falloir faire en cliquant sur le bouton Download.

S’ensuit ensuite un entrainement de notre assistant personnel.
Jouons maintenant un peu avec ce qu’on vient de configurer pour voir.
Bonjour,
Est-il possible de configurer Rhasspy en ligne de commande (j’ai fait l’installation de l’OS, des respeaker et de Rhasspy ainsi) ?
A défaut, peut-on accéder à l’interface graphique depuis un PC tiers (je me connecte en local depuis SSH actuellement) ?
Merci
Bonjour Damien,
Je ne comprends pas la question. Rhasspy ne se configure pas en ligne de commande mais au travers de l’interface web. Il pourrait être possible de le faire au travers de son fichier de configuration, mais franchement pas pratique. Pourquoi ne pas utiliser son interface web ? Depuis un autre ordi : http://IP_DE_MON_RHASSPY:12101/.
Pour accéder à l’interface graphique depuis un autre ordi, tu peux le faire via VNC si tu as activé l’option VNC : https://www.coxprod.org/domotique/chapitre-5-se-connecter-a-distance-au-raspberry/
Ced
Merci Ced pour la réponse !
En fait, l’information existe, mais je ne l’avais pas comprise comme telle (il me semblait que la seule manière d’accéder à Rhasspy était depuis la machine avec un écran en se servant du navigateur de la Raspberry).
Juste pour les débutants comme je le suis, une organisation plus “didactique” des tutos serait plus confortable (genre respeaker-docker-config de base), mais ça reste tout à fait accessible !
Question bête : pas besoin de mot de passe pour se connecter à Rhasspy en local ?
Par ailleurs, truc bête, dans ton tuto installation docker, l’information n’est pas visible (instruction pull en gris sur fond gris… imagine mon désarroi quand, comme moi, on suit “à la lettre” ton tuto car on débute ! j’ai cru qu’il fallait que je trouve l’info sur le web !).
Bref merci encore pour ton travail très utile pour moi !
Bonjour Damien,
Effectivement, il n’y pas d’authentification pour se connecter à Rhasspy. Je crois me souvenir que c’était en cours de réflexion dans l’équipe 🙂 . il faudrait que j’aille refaire un tour sur le site.
Pour le petit bug de l’article de l’install avec Docker, cela a été corrigé, merci beaucoup 🙂 !
Ced
Bonjour Cédric
Problèmes résolus
J’ai suivi ton conseil et suis allé modifier les configs comme ci-dessous
la config audio playing : sysdefault:CARD=seeed2micvoicec
la config recording : default:CARD=seeed2micvoicec.
…… Et miracle ça fonctionne, je vais pouvoir poursuivre …..
Merci pour ton aide et l’ensemble de tes tutos
JeanBa
Bonjour Cédric
Merci pour votre réactivité.
La version installée sur mon raspberry Pi3 B+ : Raspberry pi OS lite
La version de rhasspy : 2.5.7 (sur docker)
Lorsque je fais un docker inspect j’obtiens ceci :
“Devices”: [
{
“PathOnHost”: “/dev/snd”,
“PathInContainer”: “/dev/snd”,
“CgroupPermissions”: “rwm”
}
],
Lorsque je clique sur Wake up j’obtiens les log suivant:
[ERROR:2020-11-13 06:43:27,696] rhasspyserver_hermes:
Traceback (most recent call last):
File “/usr/lib/rhasspy/.venv/lib/python3.7/site-packages/quart/app.py”, line 1821, in full_dispatch_request
result = await self.dispatch_request(request_context)
File “/usr/lib/rhasspy/.venv/lib/python3.7/site-packages/quart/app.py”, line 1869, in dispatch_request
return await handler(**request_.view_args)
File “/usr/lib/rhasspy/rhasspy-server-hermes/rhasspyserver_hermes/__main__.py”, line 866, in api_listen_for_command
handle_captured(), messages, message_types
File “/usr/lib/rhasspy/rhasspy-server-hermes/rhasspyserver_hermes/__init__.py”, line 959, in publish_wait
result_awaitable, timeout=timeout_seconds
File “/usr/lib/python3.7/asyncio/tasks.py”, line 449, in wait_for
raise futures.TimeoutError()
concurrent.futures._base.TimeoutError
[DEBUG:2020-11-13 06:42:57,671] rhasspyserver_hermes: Publishing 180 bytes(s) to hermes/asr/startListening
[DEBUG:2020-11-13 06:42:57,670] rhasspyserver_hermes: -> AsrStartListening(site_id=’default’, session_id=’88d31da7-0c9a-4118-b546-9dd5f455c738′, lang=None, stop_on_silence=True, send_audio_captured=True, wakeword_id=None, intent_filter=None)
[DEBUG:2020-11-13 06:42:57,668] rhasspyserver_hermes: Waiting for transcription (session_id=88d31da7-0c9a-4118-b546-9dd5f455c738)
Petite précision : je ne suis qu’un amateur en informatique qui apprend aux travers de tutos comme celui-ci.
Je vais continuer encore à chercher….Si vous avez d’autres pistes , je suis preneur
Merci d’avance
JeanBa
Bonjour JeanBa,
Ton timeout ne semble pas du wakework donc mais de l’ASR qui n’arrive pas à enregistrer le son provenant du micro.
Il y a donc effectivement un problème avec le son. Si le son fonctionne sur le raspberry (en tant qu’utilisateur pi et non root), le problème vient de la config de Rhasspy.
Au cas où, teste ceci :
aplay /usr/share/sounds/alsa/Front_Left.wavPeux tu aller dans la config audio playing et recording et sélectionner le périphérique par défaut ?
Après, sans l’avoir entre les mains et par commentaire interposé, c’est compliqué de diagnostiquer. En ce moment, pour les tutos, j’ai rejoué énormément les tutos d’install Docker, venv et le tuto respeaker (ça me permet de vérifier qu’ils sont toujours ok 🙂 ) et je ne rencontre pas ce problème. Si tu es toujours en test et que ton raspberry n’est dédié qu’à ces tests, je t’invite à reflasher ta carte SD avec un raspberri pi OS vierge et rejouer à la lettre ces tutos.
C’est un peu le problème avec Docker. Quand il faut diagnostiquer, c’est un peu la galère :/
Ced
Ced
Bonjour
Merci pour le partage et bravo pour la qualité de vos tutos.
J’ai néanmoins un p’tit problème . Après plusieurs installations je bloque toujours au même endroit:
– Installation de Respeaker 2 MIC –> OK
– Essai du micro et de la sortie audio du Respeaker 2 Mic –> OK
– Installation de docker et du container rhasspy/rhasspy –> OK
– Configuration de Rhasspy –> OK
ET c’est là que ça bloque :
1. Lorsque je teste la fonction “Speak” la sortie audio du Respeaker ne fonctionne pas.Par contre cela fonctionne avec la sortie audio du raspberry pi3.
2. Lorsque je teste la fonction “Wake Up” j’ai une erreur:”TimeoutError”.
Si Quelqu’un a une idée…? Merci d’avance.
JeanBa
Bonjour JeanBa,
Pour le soucis audio, es tu sûr d’avoir ce paramètre dans ta ligne de commande :
--device /dev/snd:/dev/sndAttention, si tu es avec un raspberry avec interface graphique, Docker semble parfois réagir bizarrement.
Pour le problème du Wakeup, il faudrait que tu regardes dans les logs ce qui est écrit quand tu appuies sur le bouton. Le problème doit y être décrit.
Tiens nous au courant 🙂
Ced
Adaptation des “Menu” et des “valeurs” pour la version 2.4.20 :
– “Audio Recording” -> “Microphone”
– “Text To Speech” : ‘fr’ -> ‘fr-FR’
– “Audio Playing” -> “Sounds” mais ATTENTION : Bug ! Impossible de conserver le choix ‘aplay’ avec la valeur ‘”default:CARD=seeed2micvoicec: Default Audio Device”
Il m’a fallu saisir manuellement le texte suivant dans le ‘profile’ accessible via l’onglet [Advanced”] :
“sounds”: {
“aplay”: {
“device”: “default:CARD=seeed2micvoicec”
}
puis [Save Settings]
ATTENTION a ne plus cliquer sur [Save Settings] depuis l’onglet [Settings] au risque de faire disparaitre cette modif.Conversion des “Menu”cdans la version 2.4.20 :
Bonjour,
Merci pour ce document “pas à pas” qui m’a permis de commencer à configurer mon premier assistant vocal avec la version Rhasspy 2.4.20
Cependant, l’interface graphique ayant beaucoup évoluée (avec quelques bugs) je te propose de fournir si tu le souhaite les copies d’écran équivalentes pour cette nouvelle version.
En attendant, j’apporterai quelques précisions nécessaires pour que ton “mode d’emploi” soit fonctionnel avec la version 2.4.20 dans les pages suivantes.